How AI Improves Searching Document Content

We will explore how we can use AI to enhance searching document contents, using embeddings, vector stores and similarity queries to answer questions using local large language models (LLM).
Looking for expert assistance in software development? Discover how Tier 2’s custom software solutions can elevate your digital initiatives. Talk to Tier 2 for a bespoke software solution leveraging industry-standard Java technologies, agile development, and user-centric design.
In one of our previous blog’s, we explored extracting data from PDF invoices with Spring AI and OpenAI API. Now, discover how we enhance user experience by leveraging AI embeddings in document searches.
We will look at how we give our users a better experience when trying to find content from within our documentation, by turning these digital documents into AI embeddings that may be used within the prompt template passed to a local LLM.
LangChain4J framework is an open-source library, based on LangChain the open-source Python project, and is used for integrating large language models in your Java application. It has support for numerous AI models, embedding models and vector stores, document loaders and splitters, output parsers and more.
Written by Paul Thorp, Head of Verticals/Insurtech
Why might we want to search content from a document?
In a business, it is likely that over time, or before you start out, you create a library of internal documents. Possibly these are stored on a company server, or in a shared company directory, such as OneDrive or Google Drive, and are shared with your team members. Initially, this can work well but, as a business grows, so does this library as well as the number of people who need to access it. There will become a point at which trying to find the relevant information will become cumbersome, necessitating hunting through many folders and files, potentially opening, and scanning through multiple files, before they reach the desired document or section of text. Therefore, we will need a better way to digitise this data and search to find what you need.
In the past, the traditional approaches would most likely have been accomplished either using a relational database, elastic search, or Lucene indexes. These rely on pre-built indexes and structured queries for matching and ranking results: they do not ‘understand’ what is being asked, so it can still be hard to find what you want.
By harnessing AI to study and understand documents, with prompt engineering, we can find what we need faster and more accurately than before, as the model interprets and generates responses based on the input. Providing your users with a search engine that can interpret the meaning of the question, allowing users to communicate their requests more naturally, can only lead to a more intuitive user experience.
How does the AI understand our documents?
As we mentioned last time, the prompt is the text that we pass to the AI model that describes what we are asking for, as well as the desired completion response type. It would be great if we were able to pass the entire contents of a large document, containing hundreds or thousands of pages of text, in our prompt, along with a question relating to this content, and the AI model could use that to answer the question. Unfortunately, each AI model has a size limit for the request / completion and will either return an error, or result in a limited response, when this limit is reached.
So, we need a way of limiting the content we send, to send only content that is relevant to our query and, to do that, we use embeddings.
What exactly are Embeddings?
Embeddings are a way to represent words, or other data, as vectors in a high-dimensional space, i.e. a list of floating-point numbers, and can be thought of as pointers that have a length and direction, in multiple planes, in a 3D space. The vector values show how similar the text or data are, where related data points would be grouped close together and unrelated data points further apart.
For instance, as a very simple example, if we have 2 embeddings, such as “I like football”, “It is sunny today” and we perform a similarity search with the term “What is my favourite sport?”, it will return “I like football” because this is related to the term.
The vector embeddings have a wide range of applications from search, text classification, summarisation, translation, and generation, as well as image and code generation. Therefore, for our example, we will create our embedding vectors from the document text, so they can be queried later.
Vector Stores and Similarity Searches
We need somewhere to store these embeddings and for that, we use a specific store called a Vector Store or Database. These support standard CRUD operations (creating, reading, updating, and deleting data), indexes, etc. and store the vector embeddings for fast retrieval via metadata filtering and similarity search.
Traditional databases rely on structured queries to find specific matches, where we are usually querying the value that exactly matches our query. A similarity search from a vector database uses a combination of different algorithms, where it compares the indexed query vector to the indexed vectors in the datastore, to find the closest in mathematical space, i.e. items that are similar.
LangChain4J has support for most embedding provider’s methods and integrates with most popular vector stores, such as Chroma, Elastic, Milvus, PGVector, Pinecone, Redis and Weavite.
You should review each vector database to understand which will be best suited for your needs. For our example, we will be using the Chroma vector store, which can be done using the available Docker container.

Creating the Embedding Documents
First, we need to split the text from our documents into contextual bite-size chunks that we can store in the Chroma store. We do not want the blocks to be too large, so it is usually at the paragraph or sentence level, or around a maximum of 280 tokens. Essentially, each block should have enough content so that our similarity search works appropriately, but always keeping the prompt limit in mind when inserting the matched embeddings in our prompt.
There are several libraries available to extract the raw text content from your document, such as PDFBox or Apache POI. You can either write your own implementation using these libraries, along with the custom code to split the text into the required block sizes and create the required objects for each to store in the vector database, but, for convenience, these come out-of-the-box with LangChain4J to simplify this process in just a few lines of code and a few Spring beans.
The Chroma EmbeddingStore, at the most basic, just requires the Chroma server URL and name of the collection, which will be created if it does not exist already.

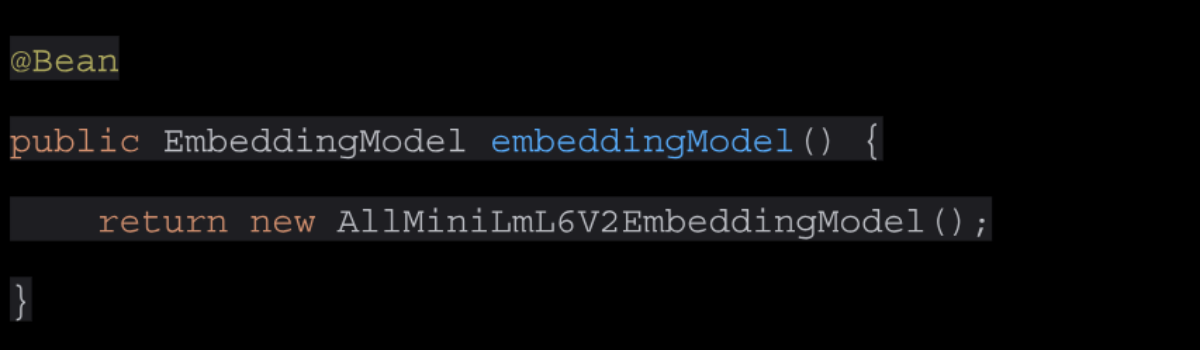
A bean specifying the EmbeddingModel to use.
And create the EmbeddingStoreIngestor that will store our text segments into the vector store. Here we specify that it uses the DocumentByParagraphSplitter to split the document text. It does this first by paragraphs, adhering to the segment size defined, e.g. 380, fitting as many as possible into a single block and deferring to use a sub-splitter, if the paragraph is too long.

Now that we have our configuration classes, we can easily use these in our application code to parse the document text and ingest, to create our embeddings in the vector store.
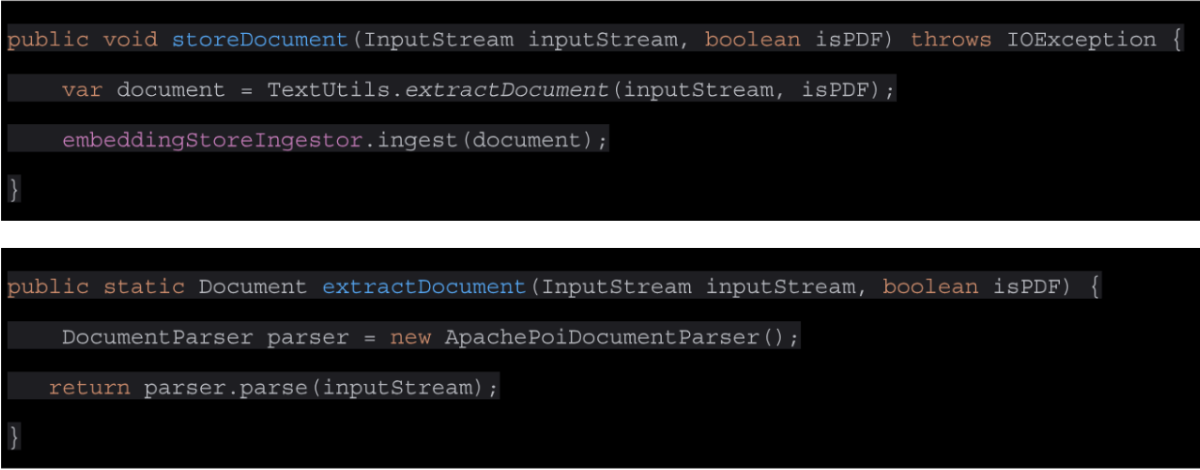
All the complexity has been removed and we can now start to use the embeddings to create our prompts.
How do we use Embeddings in our search?
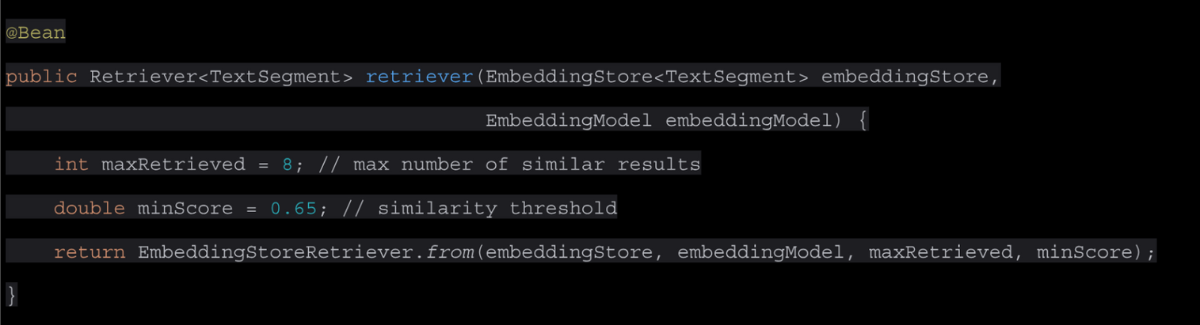
First, we need to create the configuration bean that will be used to perform the similarity search and retrieve the embeddings data. Here a maximum number of similarities is specified and the threshold value that should be used, ranging from 0 to 1, where values closer to 1 indicate higher similarity. You should adjust these values to find the ideal settings based on the nature of your data and the embedding model you are using.
Next, we simply define an interface containing the System message that will be used in the prompt. Remember, the AI model cannot understand what it needs to do without clear and precise instructions, so carefully construct this, with a clear intent of what you require.
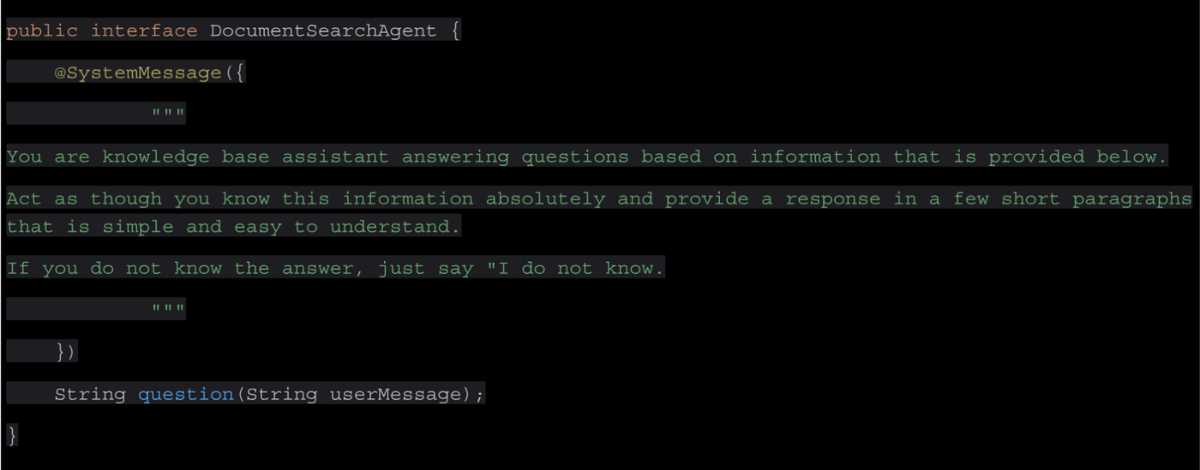
Our final configuration class creates the implementation of our DocumentSearchAgent, using the specified retriever.

We can now use this search agent in our services to do all the heavy lifting and we just need to supply the question from the user.

Why use a local LLM and what is Ollama?
Using a commercial AI and LLM means that you are sending your data outside of your environment and this may present a security concern. Running an LLM locally means that the data is kept private, allowing you to be able to comply with any specific regulations, which may be important when dealing with sensitive or proprietary data. Also, other than hosting, there are no additional costs incurred each time you interact with the LLM.
Ollama is a platform that allows you to run open-source large language models, such as Llama 2, locally. It currently supports more than 60 different models, including Llama 2, Mistral, Orca2, Starling, Code Llama, to name but a few. Each of these models has different qualities and abilities, from code creation, summarisation, and text generation, through to chatbot text, so it is important to use the model most appropriate for your needs. View the documentation on the Ollama website for more information, including installation and CPU, GPU and memory requirements to run both the server and specific LLM models.
For simplicity, to get up and running quickly, there is a Docker container available.

Testing the search
I have started my server and uploaded a couple of sample company documents. The first document is an article taken from a previous blog, talking about a specific project for one of our customers.
So, I hear you ask, in what way did Tier 2 Consulting help their customer for this project? Well, let’s ask our document search agent.

So, was the client pleased with the approach and outcome of the project?

And, finally, what client feedback was given, based on the results of the project, and how did Tier 2 feel?

The other document is also from our blog, where a leading London broker had an idea to revolutionise their business and enlisted the guidance of our technical team.
What was the purpose behind the project and how did we help?

And what was the purpose and goal of the project?

What benefit was there for their brokers and their processes?

Summary
We have shown how it is possible to ask questions ‘about’ our documents, rather than just searching for text, resulting in more meaningful answers, while keeping all the data private via a local LLM. Although just a simple example, this shows how this approach could be used for many different applications, such as a FAQ chatbot, support documentation search and much more. Using the Spring Boot and LangChain4J APIs made it possible to simplify the integration of AI/LLM capabilities into your Java application.
How can Tier 2 help?
If you’re in search of expert assistance in software development, Tier 2 is your dedicated partner. Reach out to discuss your specific requirements and discover how our custom software solutions can elevate your digital initiatives. Come to us for a bespoke software solution leveraging industry-standard Java technologies, agile development, and user-centric design.


