Deep Dive into Ceph: Exploring the Power of Clustered Storage

Written by Jonathan Gazeley
Welcome to our comprehensive blog post, where we take you on a deep dive into the world of Ceph, a remarkable clustered storage engine. If you’ve been seeking a resilient and scalable storage solution that can seamlessly span multiple computers, then Ceph might be the perfect fit for your needs. In this article, we will explore the fundamentals of clustered storage, delve into the different storage types supported by Ceph, and discuss various deployment options available. Whether you are a system administrator, a developer, or an IT professional looking for a robust storage solution, join us as we unlock the potential of Ceph and its significance in the modern computing landscape.
Let’s get started by understanding the core concept of clustered storage and how Ceph revolutionises traditional storage systems.
What is clustered storage?
Clustered storage is any kind of storage system which runs across multiple computers (called nodes), for resilience. Each node will have at least one dedicated storage device (i.e. a hard drive, SSD, or NVMe) that it contributes to the storage pool. Ceph calls these storage devices OSDs. The pool is simply the size of all the different devices added together. Ceph has a concept of Placement Groups (PGs) which are just buckets spread across the OSDs, into which it can place pieces of data.
When you write a piece of data into a Ceph cluster, Ceph actually writes 3 replicas into 3 different PGs in 3 different OSDs within the pool. This means the piece of data remains available even if some nodes are unavailable. The number of replicas is customisable to suit your needs.
If a node becomes unavailable unexpectedly, the replicas that were on that node immediately get transferred to other nodes, to maintain 3 replicas for each piece of data.
What storage types are there?
There are three main storage types in use in modern computing clusters.
Block storage
Block storage is the simplest type of storage available. The available storage is consumed by exactly one system. On traditional non-clustered storage, you would usually use iSCSI – and in fact Ceph can present its block storage as iSCSI if you need.
Common use cases are providing storage to a virtualisation platform so it can store VM disk images as blocks, or providing ReadWriteOnce block storage to a Kubernetes pod. The Kubernetes cluster is responsible for creating the filesystem on the block storage.
File storage
In file storage, the storage cluster creates and manages the filesystem, allowing multiple systems to connect and mount the filesystem. The traditional equivalent would be NFS or Windows file shares.
File storage can be consumed by multiple Kubernetes pods simultaneously using a ReadWriteMany volume.
Object storage
Object storage is completely different from the previous two kinds, and you might know it better by Amazon’s trademark S3 storage. Object storage works over an HTTP API, with clients making requests to put and get objects in a storage bucket. It’s up to the object storage server to decide how it actually wants to arrange the objects it needs to store.
Ceph offers a basic object storage server, but if you opt for Red Hat Data Foundation it comes bundled with NooBaa which is a much more flexible object storage system that can be placed in front of multiple other object storage systems.
How do I deploy Ceph?
Ceph is an open source product, which used to be sold by Red Hat and is now sold by IBM. It also forms the core component of Red Hat Data Foundation which runs on top of Red Hat OpenShift.
There are several ways to get and deploy Ceph.
- Ceph exists as a standalone product which can be installed on any systems you can think of.
- Ceph also exists bundled with another package called Rook, which allows easy deployment and orchestration of Ceph on various Kubernetes platforms.
- Ceph is included in Red Hat OpenShift Data Foundation, along with Rook and NooBaa as an enterprise-ready clustered storage solution
Any storage system needs careful analysis of your requirements and a comprehensive design before you start implementing.
Time for a demo
Tour
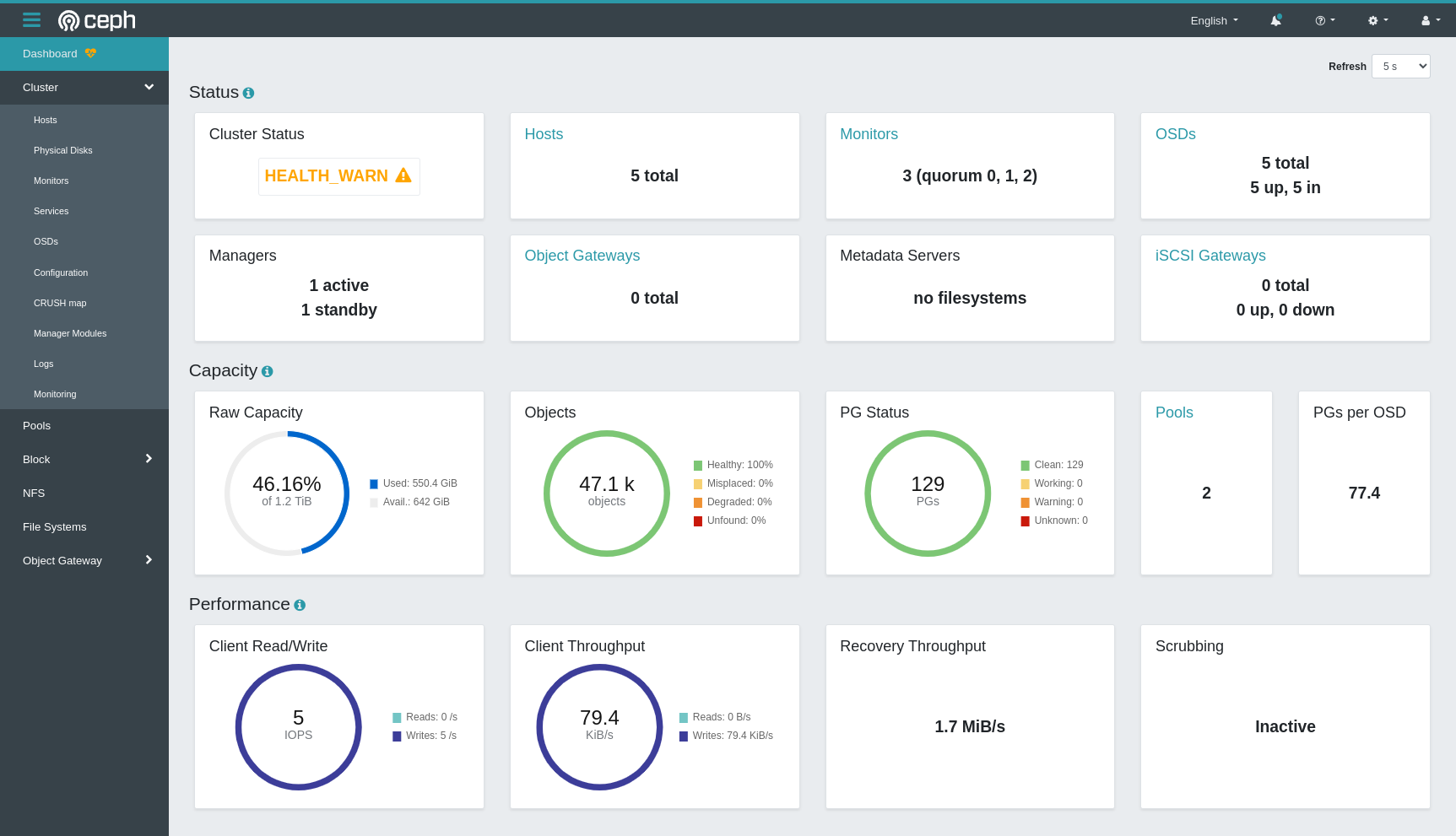
First, let’s have a look at the example Ceph setup I’ve deployed on a test cluster. The cluster is 5 small hardware nodes, each with one 256GB NVMe device dedicated for Ceph use, and is running MicroK8s with the Rook-Ceph operator, although this would be virtually identical on Red Hat OpenShift Data Foundation, or any other Ceph deployment where you enable the Ceph Dashboard.
Here’s a shot of the Ceph dashboard on my test cluster. In the top right OSDs section you can see there are 5 OSDs, giving a raw capacity of 1.2TB (although as this cluster is running 3 replicas, this gives a usable capacity of just over 400GB).
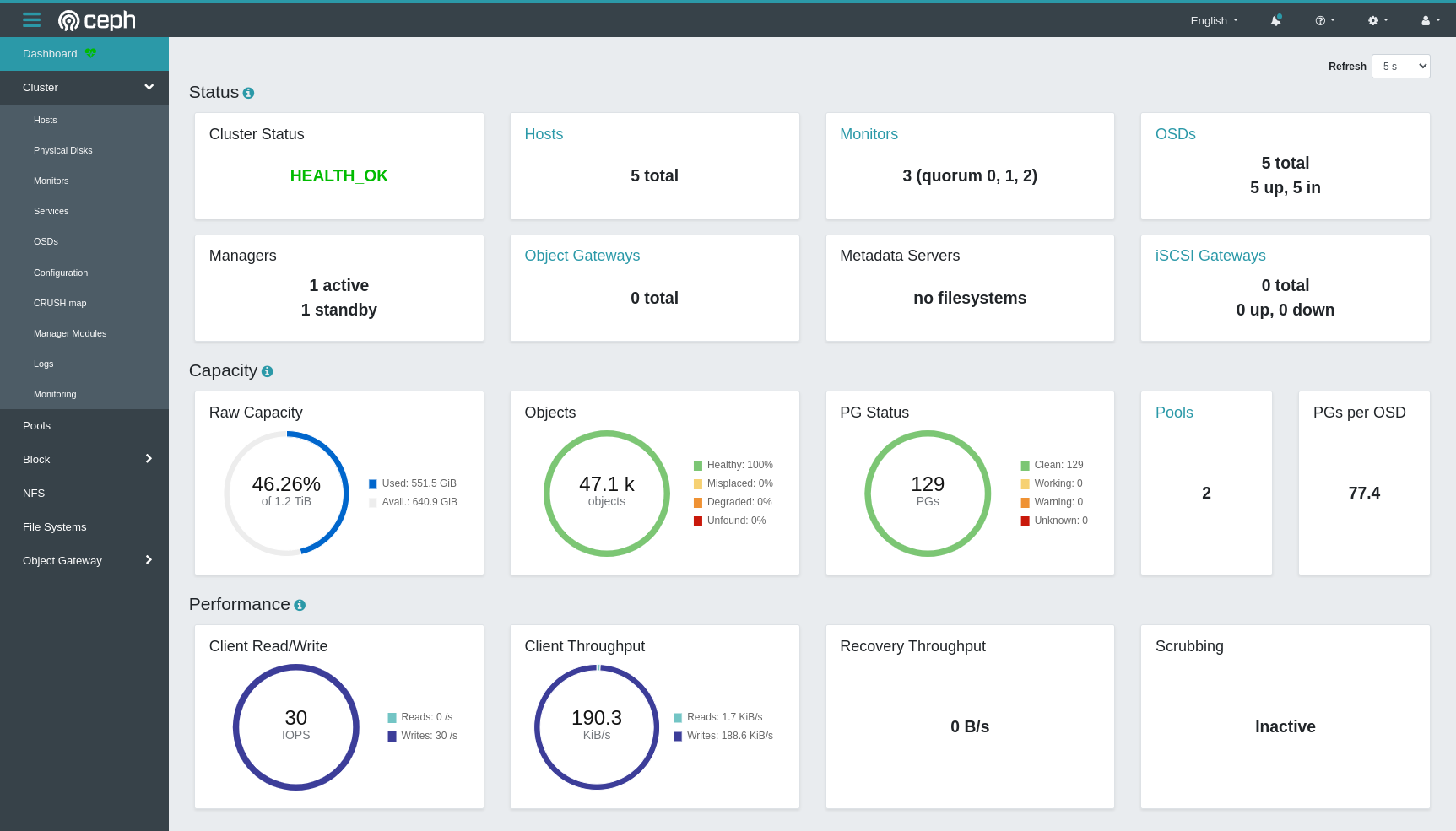
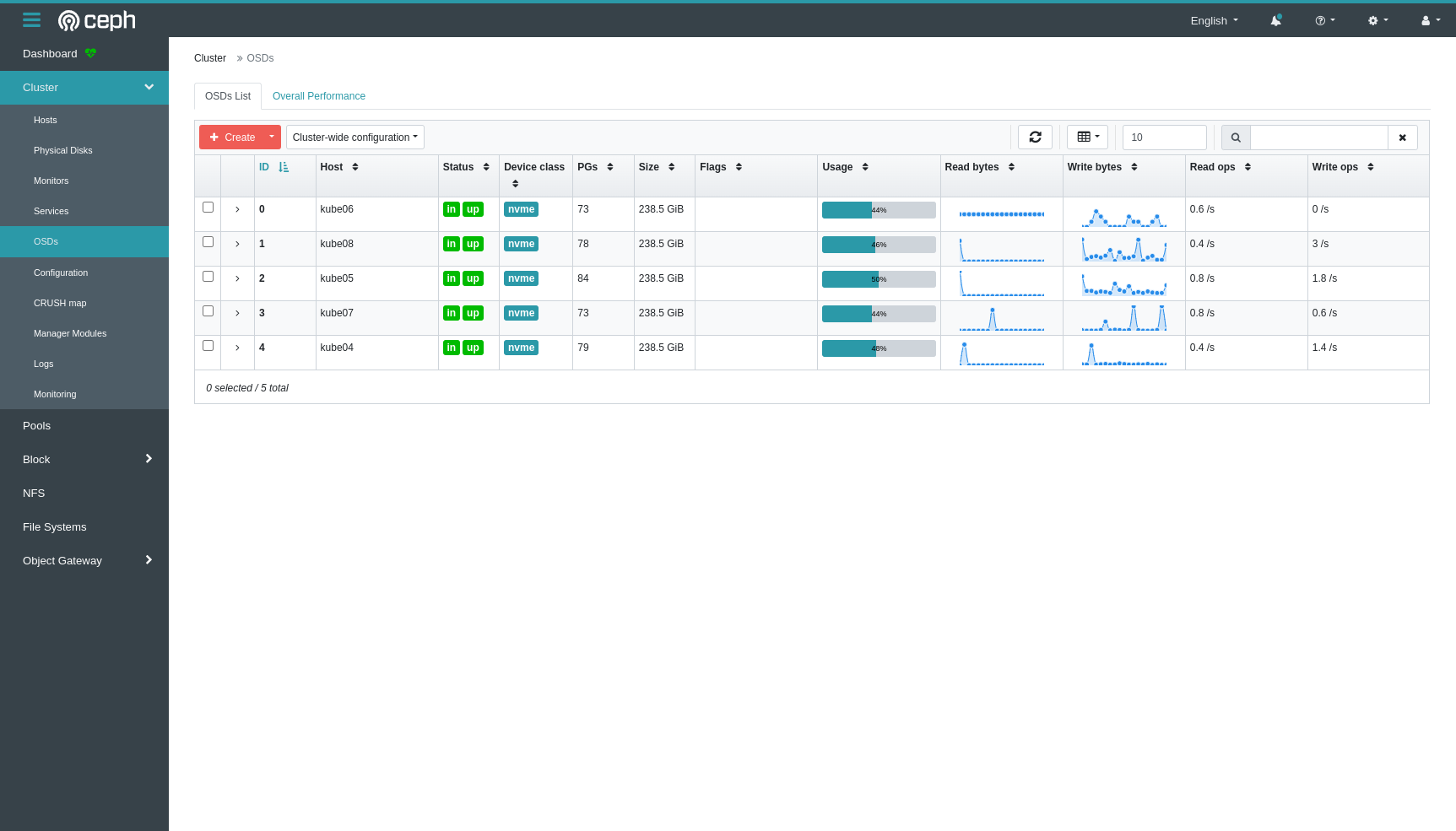
And here on the OSD page we can see 5 OSDs, one per node, all healthy.
Kubernetes provisioning
In this demo, I’ll show how simple it is to provision Kubernetes volumes on Ceph.
Every Ceph cluster has a component called the Monitors. There are typically 3 Monitors to ensure availability and quorum at all times. The Monitors are responsible for deciding which pieces of data get put on which OSD.
Each Ceph cluster also has a component called the Managers, which oversee operation of the whole cluster, and provide an API via which storage can be provisioned. This is what the Rook operator hooks into.
When Rook was installed on this Kubernetes cluster, it also created a Kubernetes StorageClass resource:
[jonathan@poseidon ~]$ kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
ceph-block rook-ceph.rbd.csi.ceph.com Retain Immediate true 86dThis StorageClass can be consumed in the usual way, by creating a PersistentVolumeClaim:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim-ceph-block
spec:
storageClassName: ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1GiHere is the created PersistentVolumeClaim which references the PersistentVolume that has been provisioned:
[jonathan@poseidon ~]$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
test-claim-ceph-block Bound pvc-f181ff77-ef26-4655-a955-745e2fe4093f 1Gi RWO ceph-block 6sWe can also take a look at the PersistentVolume itself:
[jonathan@poseidon ~]$ kubectl get pv pvc-f181ff77-ef26-4655-a955-745e2fe4093f
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-f181ff77-ef26-4655-a955-745e2fe4093f 1Gi RWO Retain Bound default/test-claim-ceph-block ceph-block 64sBy interrogating the PersistentVolume, we can get the name of the Ceph RBD image that backs the volume:
[jonathan@poseidon ~]$ kubectl get pv pvc-f181ff77-ef26-4655-a955-745e2fe4093f -o jsonpath='{ .spec.csi.volumeAttributes.imageName }'
csi-vol-f007b0cb-58a3-42ff-9973-c05cb95da56eAnd then we can find this this RBD image in the Ceph dashboard as a block image.
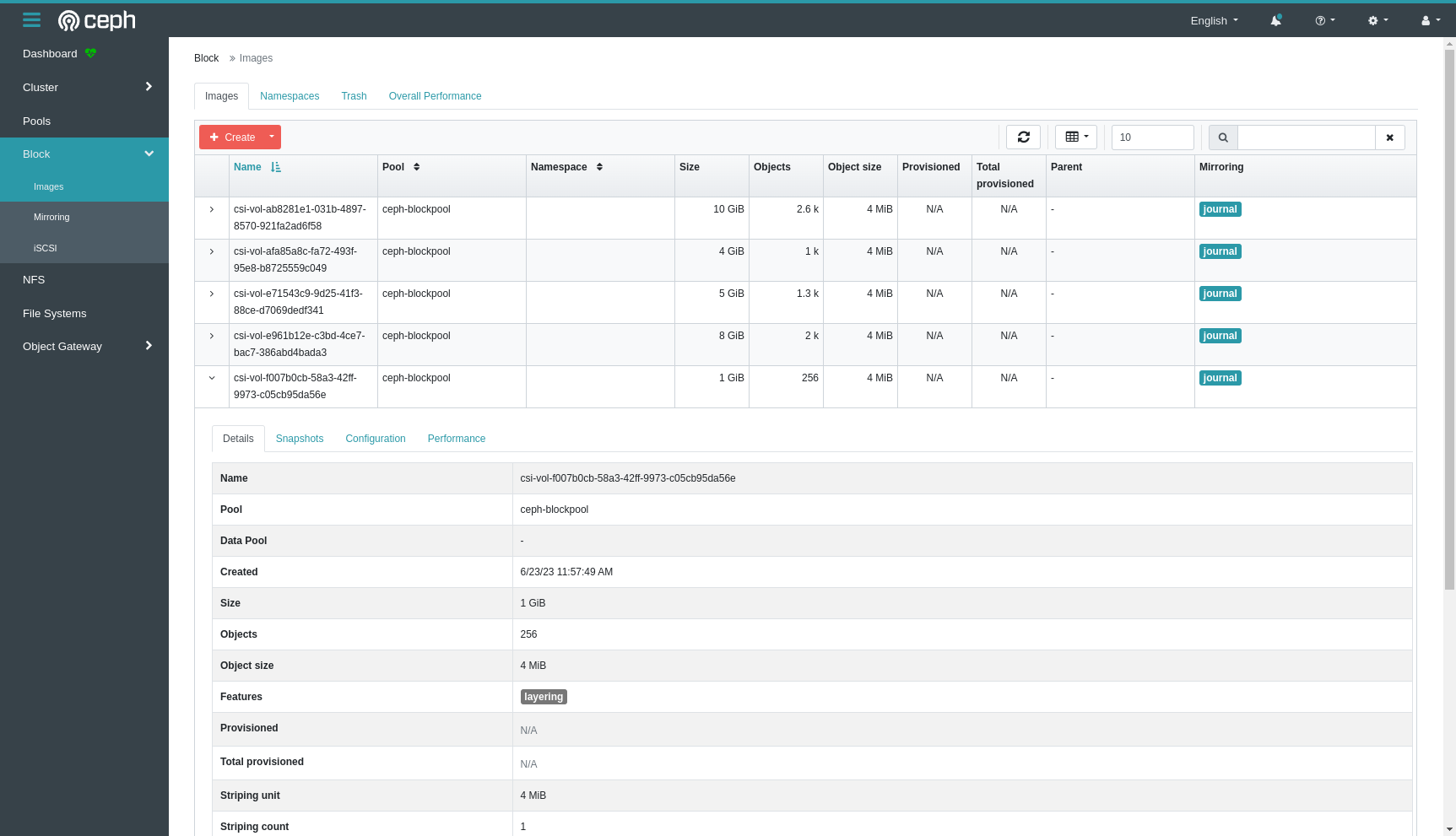
Fault tolerance
So far so good – we’ve seen how easy it is to create and use Ceph volumes once the integration with Kubernetes has been set up. But I think one of Ceph’s most impressive features is its fault tolerance.
In the second demo I’m going to simulate an outage of a node, and see how the Ceph cluster recovers. We’ll start off with a healthy cluster as above, and then I’m going to force shut down one of the nodes.
Ceph immediately notices. We can see that one of the OSDs is marked “down” and some of our objects are marked as Degraded, because only 2 of their 3 replicas are available. Cluster status is HEALTH_WARN. Of the PGs, we can see that some are Warning and some are Working. The Working PGs are recreating their third replica on an OSD that is still available. It works as efficiently as it can to restore cluster health and the full set of 3 replicas of all your data.
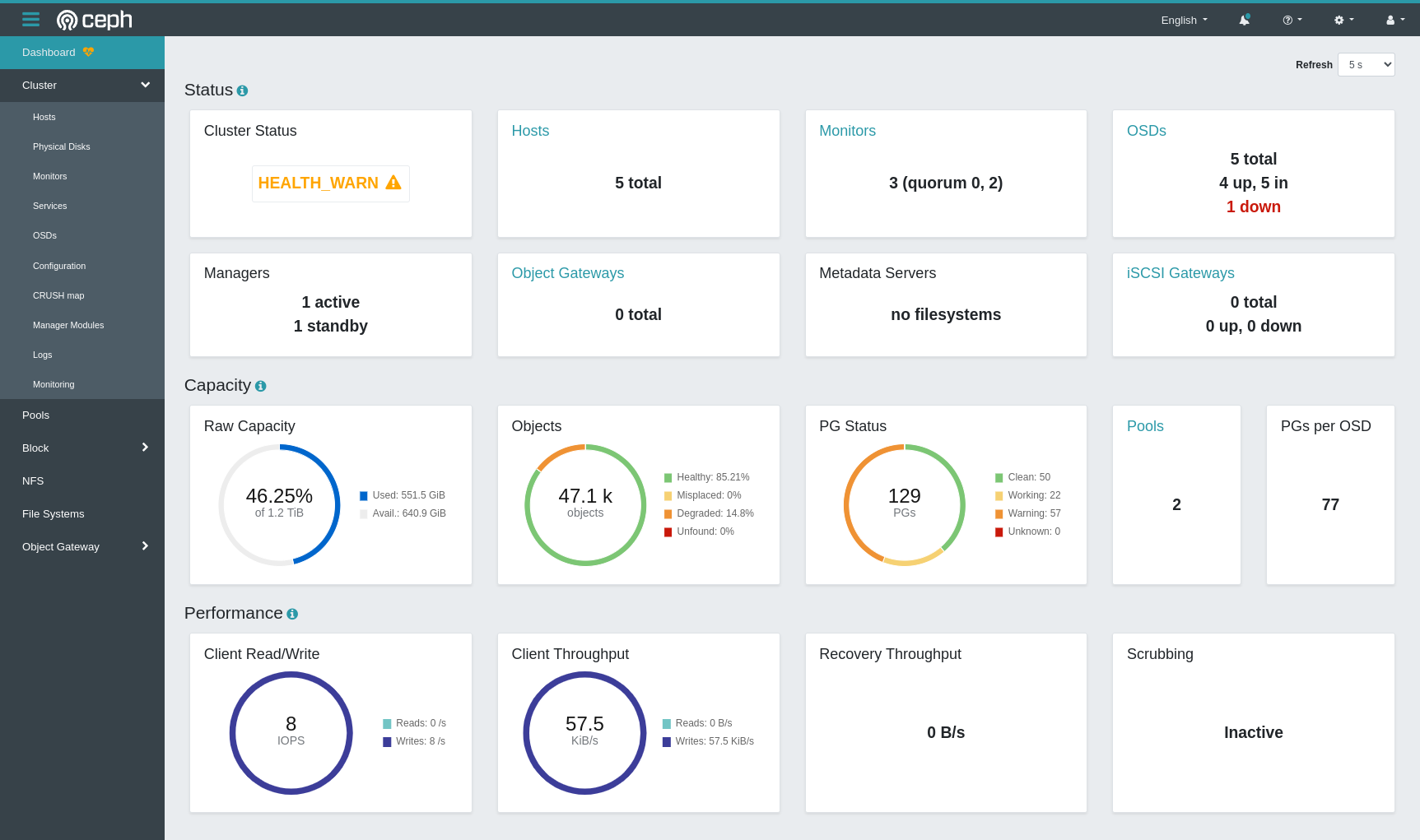
If at some time later, the broken node with its OSD comes back again, the cluster has to decide what to do. It will now have 4 replicas of the data, and one of them will be different from the rest because it has been offline.
Ceph has you covered. Through a process called Recovery, it will sync the PGs on the “stale” OSD back in line with the healthy replicas, and then reduce the number of excess replicas from 4 back down to 3. In this screenshot you can see that all the objects are now marked as Healthy as they have at least 3 replicas, but Recovery Throughput is now non-zero as it syncs the changes back to the stale OSD. When this finishes, Cluster Status will return to HEALTH_OK.
How can Tier 2 help with Storage?
Tier 2 provides a team of OpenShift Consultants with accredited Red Hat OpenShift Container Platform skills to help organisations exploit containers, and agile and DevOps processes, to modernise their applications, develop new cloud-native applications, and accelerate application delivery. This includes the add-on products like OpenShift AI.
We can help with:
- Design, installation and configuration of your OpenShift environment, including OpenShift Data Foundation
- Onboarding for OpenShift Dedicated customers
- Set-up of CI/CD pipelines
- Application modernisation to benefit from containers and cloud-native architectures
If you’re thinking of implementing a container cluster and would like to talk to a Red Hat Container Platform Specialist, please get in touch.


